4 Methodologies in Text to Image Tools |DAFTCRAFT ENGINEER BLOG

Generating images from text is one of the trending topics of AI(Artificial Intelligence) nowadays. It started in the years 2015 and 2016. In this blog, let’s see
- History of Text to image conversion
- 4 different technologies and methods are used to generate the text-to-image models.
History of Text to image conversion
One of the main reasons behind the text-to-image model is to amplify the creative potential of both humans and machines. From 2015 and 2016 different methodologies or research methods were applied to generate the text-to-image models. We can see 4 popular models
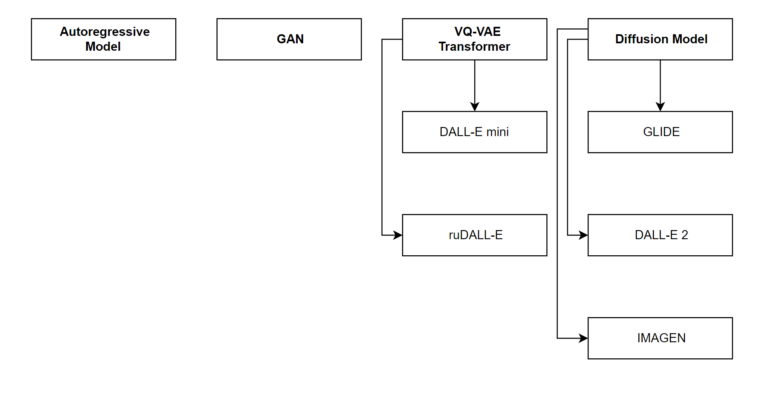
- Autoregressive model
- GAN(Generative Adversarial Networks)
- VQ-VAE Transformer
- Defusion model
The autoregressive model is the first one to release, which is in the year 2016 through the paper named “GENERATING IMAGES FROM CAPTIONS WITH ATTENTION”[1].
In 2021 and 2022 VQ-VAE transformer based text to image model started gaining importance with the 2 famous papers “Zero-Shot Text-to-Image Generation”[2] and “Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors”[3]. The models designed based on this methodology are DALL-E mini, DALL-E mega, and ruDALL-E. All the models are open source.
In recent days, the Diffusion model started gaining more importance. The first product is GLIDE by OpenAI, and the 2nd product is DALL-E is the 2nd product which is more popular and it is also by OpenAI. One more popular product is there which is IMAGEN by google. All 3 popular models belong to the Diffusion model methodology.
Let’s see in detail about all 4 methodologies.
Autoregressive model
This is the model that generates images from natural language descriptions. This model iteratively draws patches on a canvas, while attending to the relevant words in the description. After training on Microsoft COCO, this model is compared with several baseline generative models on image generation and retrieval tasks.
GAN(Generative Adversarial Networks)
Two papers ”AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks” and “Cross-Modal Contrastive Learning for Text-to-Image Generation ”showed a promise of using GAN for creating images from text.
GAN is a machine learning model in which 2 neural networks compete with each other to become more accurate in their result or predictions. There are 2 neural networks:
- Generator
- Discriminator
The generator is the convolutional neural network and the Discriminator is the deconvolutional neural network. The generator’s goal is to artificially manufacture output that can be easily mistaken for real data. The goal of the discriminator is to identify which data is artificially created, which means the generator USS the latent space and by using the latent space it creates the content, and that content is given to the discriminator to validate or predict for its correctness and the discriminator uses the real dataset and real content in order to generate the result.
There will be a back propagation between the result, generator, generated content, and the discriminator. There will be a loop in Generator and the generator will start producing more accurate results in the later stages of the loop.
VQ-VAE Transformer
It is introduced in the paper ”Zero-Shot Text-to-Image Generation” and “Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors”. To understand how it actually works, let’s look at the DALL-E mini first. This model takes images from three different datasets.
- Conceptual 12M datasets (Which contains 12 million images and caption pairs).
- Conceptual caption dataset(Which contains 3 million image and caption pairs).
- Open AI subset of YFCC100M(Which contains 15 million image and caption pairs but only 2 million is taken from that because of the storage space limitations).
In this model, the images are taken by the VQ-GAN encoder and converted into a sequence of tokens. The BART encoder takes image captions. The output of the BART encoder and the encoded image is fed through the BART decoder which is an autoregressive model whose goal is to predict on next token. The sequence of image token decodes with the help of VQ-GEN decoder and finally, the output is chosen from the clip based on the requirement.
Defusion model
These are generative models, which means they are used to generate data similar data on which they are framed.
Fundamentally they work by destroying the training data through the successive addition of Gozian noise after learning to recover the data by recovering the noising process. Let’s see talk about Google’s IMAGEN. It uses a large amount of frozen text encoder to encode text into the text embeddings. The conditional diffusion model maps the text into 64X64 images. then it utilizes the text, conditional super-resolution model, to upsample the image from 64X64 to 256X256 image and again there will be a work of super-resolution model which gain upsample the image from 256X256 to 1024 X 1024 as a final result.
This is how the different methodologies work to generate images from the text.
When we start looking for text to images on the internet, we can see the name Midjourney all over. Let’s discuss that in the upcoming blog post.
References: https://github.com/prodramp/DeepWorks/tree/main/Text2Image-AIModels

Sucheta Bhat
AI/ML Engineer